



Как создать семантическое ядро приложения?
Семантическое ядро приложения - фундамент, основа основ работы с оптимизацией мобильных приложений. Практически любая тема, которая раскрывает суть ASO оптимизации, будет касаться семантического ядра. В нашем гайде для начинающих ASO специалистов, мы коснемся источников семантики, как собрать, анализировать поисковые запросы и что с ними дальше делать.
Семантическое ядро - источники ключевых слов
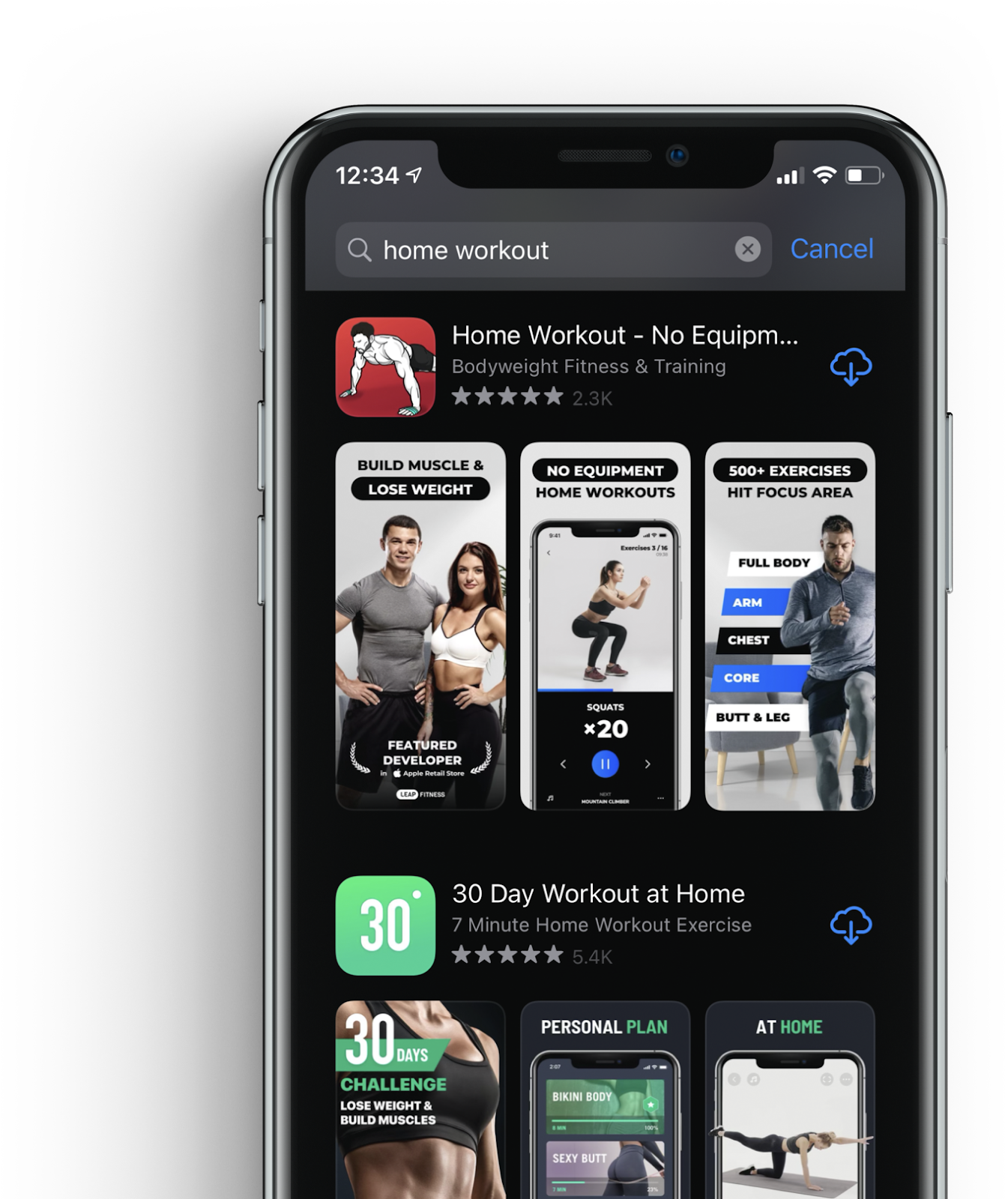
Лето на носу, поэтому интерес к хорошей физической форме никто не удивит, мы в тренде. Именно так рождается поисковый запрос - из потребности. Почти все ключевые слова и фразы это отражения нужд пользователей. Все, что каким-то образом решает проблему, удовлетворяет потребность или помогает пользователям, попадает в поле поисковых запросов. Заметьте, мы не заходим в App Store с информационными вопросами - кто убил Кеннеди или почему вымерли динозавры? Только с задачей или потребностью - доставка онлайн, медитация и звуки природы, трекер привычек.
Первый короткий вывод - запросы для семантического ядра функциональные, а не информационные
Следовательно мы, решая нашу задачу по восстановлению фигуры к пляжному сезону, уже можем сформулировать ряд поисковых запросов на этот счет:
- фитнес дома
- снизить вес
- похудеть
- домашний фитнес
На каждый из этих поисковых запросов будет своя поисковая выдача, но если проверить - почти все они будут демонстрировать, более или менее однообразный Топ приложений. Проверяем:
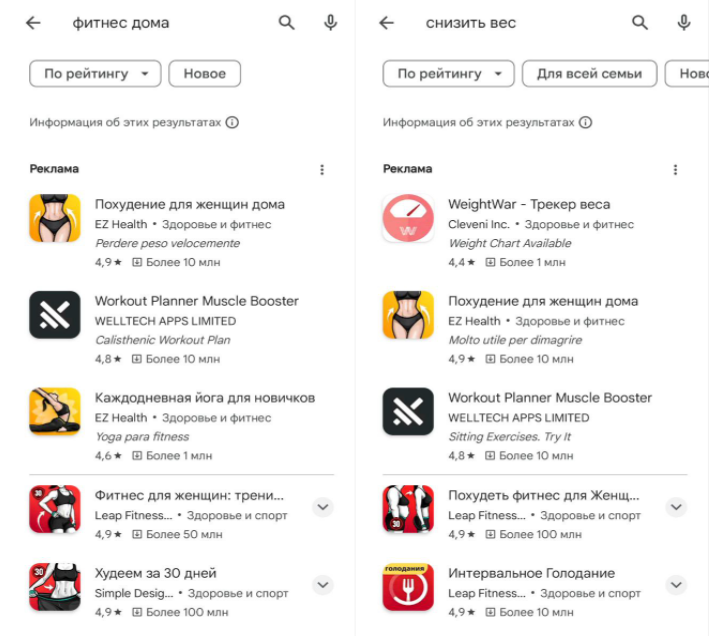
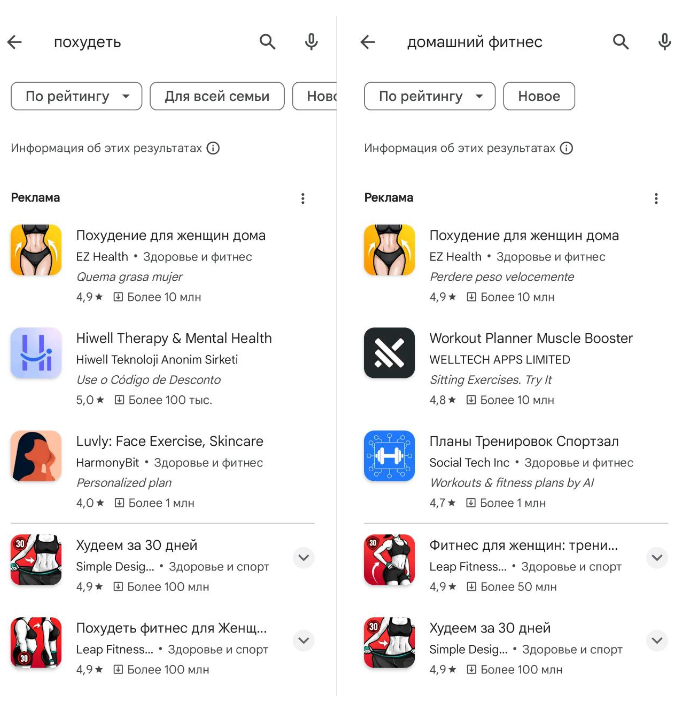
Сразу же стоит оговорить, что первые три места в выдаче - реклама (там даже есть специальный значок). И пользователю, без дополнительного скрола видны всего первых два места в поиске.
Второй краткий вывод - места в Топе очень важны, установки чаще всего будут происходить из 10-ки приложений в выдаче, хотя конечно никто не ограничивает скролить дальше. Именно это побуждает заниматься оптимизацией приложения, когда не используя рекламу, встреча с пользователями все равно возможна.
Вывод два - источники семантики это потребности пользователя, они же функционал приложений.
Теперь вернемся в магазин приложений. Только что, при вводе поискового запроса, мы скорее всего воспользовались авто подсказкой - не так ли?
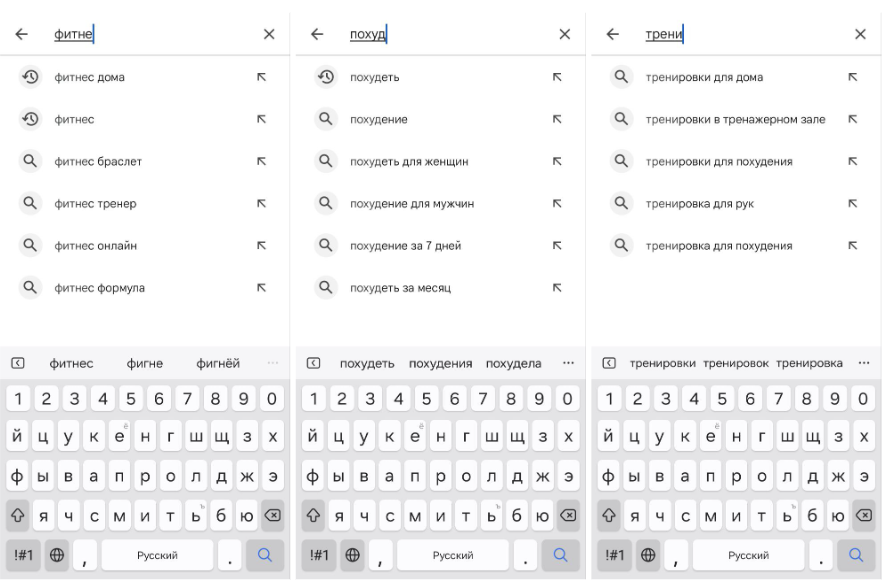
Вот так выглядит подсказка магазина приложений - это уже существующая история запросов такого типа среди пользователей. Таким образом стор подсказывает и экономит наше время, а еще работает, как уточнение - нас интересует фитнес, но какой? Так мы сможем выбрать более точное соответствие нашим ожиданием - фитнес для дома, фитнес браслет, фитнес для похудения. Но если наша задача состоит в том, чтобы собрать максимально много подходящих нам запросов, то подсказки - ценный источник. Так мы из четырех запросов “просто из головы” получаем по семь-восемь подсказок от магазина и вуаля - наш список уже похож на список.
Вывод три - подсказки от магазина являются ценным источником семантики.
На что еще мы можем обратить внимание при сборе наших ключевых слов? На конкурентов. Те самые приложения, которые очутились в поисковой выдаче по интересующим нас запросам (не отходя от примера, пусть будет приложение для фитнеса). Мы можем посетить страницу каждого из них и ознакомиться с информацией, которая там размещается. Пока, не углубляясь в дебри текстовой оптимизации, мы скользим по поверхности поисковой выдачи.
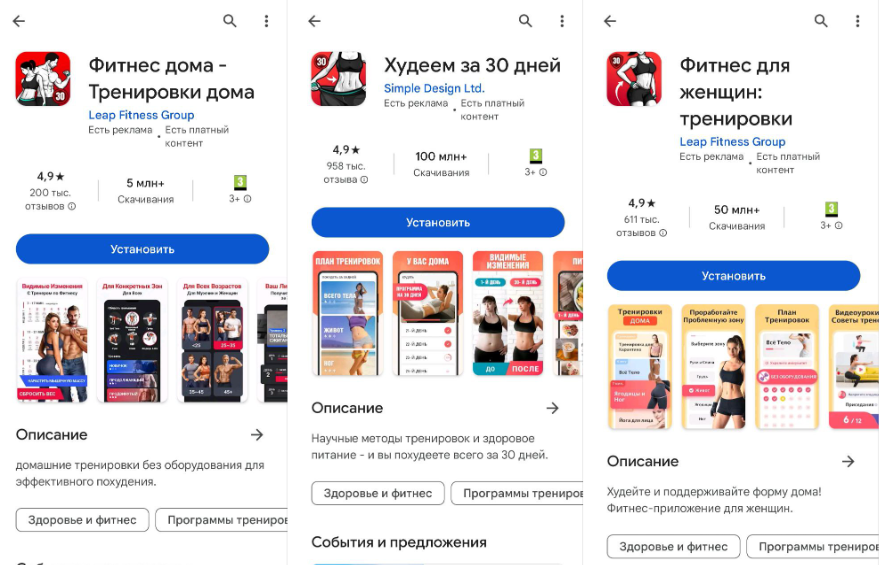
Просматривая название и начало описания приложений в Топе поисковой выдаче, мы добавляем в наш список новые ключевые релевантные фразы - “фитнес для женщин”, “худеем за 30 дней”, “тренировки дома”, “домашние тренировки”, “здоровое питание”.
Итак, без задействования тяжелой артиллерии, в виде аналитических инструментов, мы исчерпали наши возможности по сбору поисковых запросов, но основной посыл - понять взаимосвязь, между тем, что ищет пользователь, как формируется ключевые запросы и что отражается в поисковой выдаче. С этим мы справились.
Краткий вывод - потребности пользователя, которые привели его в магазин приложений, будут лежать в основе семантического ядра релевантного приложения. осталось только прояснить несколько терминов:
- релевантность это соответствие всех трех признаков, потребность от пользователя - запрос в магазин приложений - подсказка и ключевая фраза.
- ключевые слова, поисковые фразы, ключи - это все абсолютно одинаковые понятия, которые представляют собой словесное выражение потребности пользователя.
- поисковая выдача это перечень приложений или игр, которые магазин приложений формирует под каждый запрос.
- когда происходит показ приложения в списке по ключевому слову, это называется индексация или то, что приложения проиндексировано по этому поисковому запросу.
Думаю уже стало совершенно ясно, что запросы пользователей соотносятся с теми фразами и словами, которые находятся на странице приложений. Они содержаться в их названии, описании и подзаголовке - что общим словом называется метаданными приложения. Именно для них мы будем формировать наше семантическое ядро.
Наша основная задача, кроме списка ключей - дать понять магазину приложений, по каким поисковым запросам пользователей нас нужно показать. Все это происходит исходя из метаданных и учитывает, магазин приложения - где мы размещаемся. Обещаем, что в самом конце все станет кристально ясно, а пока вернемся к истокам, а именно к семантическому ядру.
Суть семантического ядра приложения
Основная цель создания списка ключевых слов, он же семантическое ядро - это сопоставить пользовательские запросы во всех их разнообразии и функционала приложения. Это значит, что наша задача, не только найти и собрать список ключевых слов, но и отфильтровать их по двум признакам:
- согласно тем запросам, которые совершают пользователи в магазине.
- согласно релевантности приложения или игры.
Простой пример, чтобы расставить все точки над и:
Приложение интервальный таймер - представляет собой набор всевозможных таймеров для функционального тренинга, от банального секундомера, до настраиваемых временных промежутков. Все поисковые запросы “таймер для тренировок”, “wod таймер”, “таймер для кроссфита” - подходят и ложатся в основу семантического ядра. А вот очень схожие по смыслу “кухонный таймер”, “таймер для готовки” вообще не релевантны. Конечно, с этим можно поспорить, и сварить яйца можно и под тренировочный таймер, но вряд ли мы сможем убедить в этом пользователей. Релевантность ключевых слов мы проверяем максимально простым и прозрачным соответствием их функциям приложения с одной стороны, задачами пользователей с другой стороны.
Далее, стоит отметить, что поисковые фразы могут быть действительно фразами (несколько слов, предлоги и союзы), а могут быть одним или двумя словами. Благодаря авто подсказкам, пользователю не нужно много печатать, а просто выбрать из списка. Именно поэтому в эпоху краткости и сокращений, мы все еще видим длинные поисковые фразы (но обычно это не более 4 слов).
Начинать формирование семантики мы можем, как и в этом гайде - с логики и смысла приложения. Потом, мы пойдем за подсказками магазина - посмотрим там не только перечень возможных участников нашего ядра, но и сами формулировки. Каким образом, какой порядок слов, склонения и формы используются нашими потенциальными юзерами. И тут, по сути, наши возможности исчерпываются, а список слов может оказаться довольно коротким. Следующий пункт нашего гайда позволит нам значительно его расширить и сделать максимально информативным.
Семантическое ядро приложения - список релевантных поисковых запросов. Но кроме признака “подходит под функционал приложения”, мы приходит к очень важному показателю ключевого слова - популярность поискового запроса. Как много пользователей вообще потенциально интересуются тем или иным запросом. И тут пора упомянуть не только качественные характеристики ключевого слова, но и количественные. Трафик - один из важнейших показателей ключевых слов. Именно этот показатель демонстрирует нам, сколько пользователей в день искали тот или иной запрос в магазине приложений. И вот тут, нам уже не обойтись без специальных аналитических инструментов. Мы подробно и пошагово пройдемся по возможностям аналитики, и соберем наше семантическое ядро. А пока давайте подытожим про ключевые слова:
- По смыслу:
- релевантные
- нерелевантные
- По длине:
- short tail - поисковые запросы из двух или одного слова
- long tail - ключевые фразы из нескольких слов
- По трафику:
- высокочастотные
- среднечастотные
- низкочастотные

- Основы ASO для приложений в Google Play и App Store
- Создание и анализ семантического ядра
- Текстовая оптимизация App Store и Google Play
- Иконка, скриншоты, видео. A/B тестирование
- Фичеринг. Подборки. Рейтинг. Работа с отзывами
Аналитические инструменты по формированию семантики
Для того, чтобы найти ключевые слова, со всеми необходимыми нам характеристиками и показателями, мы обратимся в аналитику мобильных приложений ASOMobile. Здесь есть очень широкий инструментарий по анализу не только ключевых слов, но и конкурентов, рынка мобильных приложений, показателей загрузок и доходов и многого другого. Но мы сосредоточимся на фундаменте оптимизации - семантическом ядре.
Даже, если наше приложение находится только на этапе идеи, мы уже можем обозначит задуманный функционал, а следовательно - определить конкурентное поле. Почему это важно? Потому что мы будем собирать семантику не из воздуха, а на основе аналитических данных.
Входящая информация - список слов, который у нас уже есть исходя из логики, функционала и подсказок магазинов. Основные конкуренты - схожий функционал и, желательно, высокий уровень установок. Мы выбираем нашу путеводную звезду и на ее основе будем формировать семантическое ядро.
Мы не будем далеко отходить от идеи домашнего фитнеса, но как найти то самое приложения, которое послужит нам и базой и примером? Аналитические инструменты послужат нам и здесь - Топ приложений в каждом маркете и выбранной стране выглядит вот так:
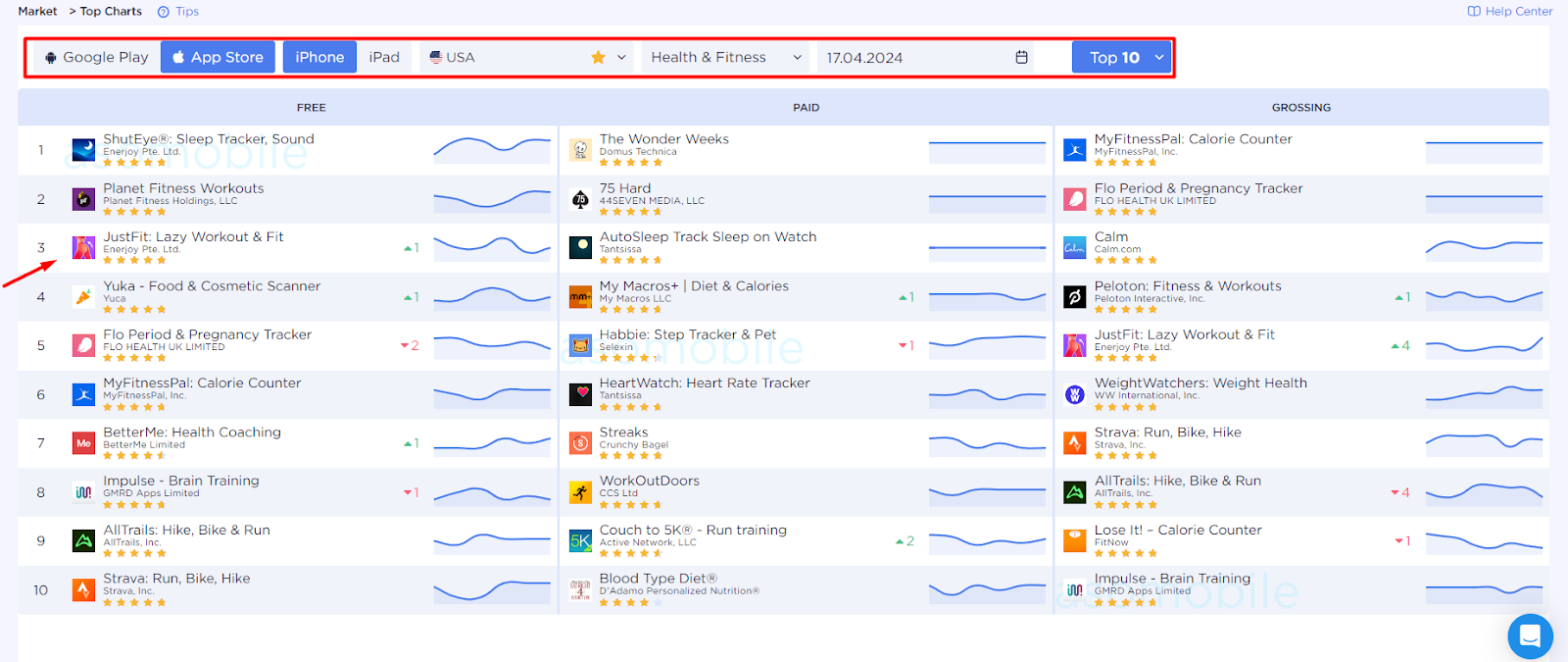
В 10-ке топа категории Health & Fitness нашлось приложение, которое максимально схоже с нашим, имеет идентичный функционал, то есть оно является наши релевантным конкурентом.
Приложение - JustFit: Lazy Workout & Fit, которое в App Store находится на третьем месте по популярности у пользователей.
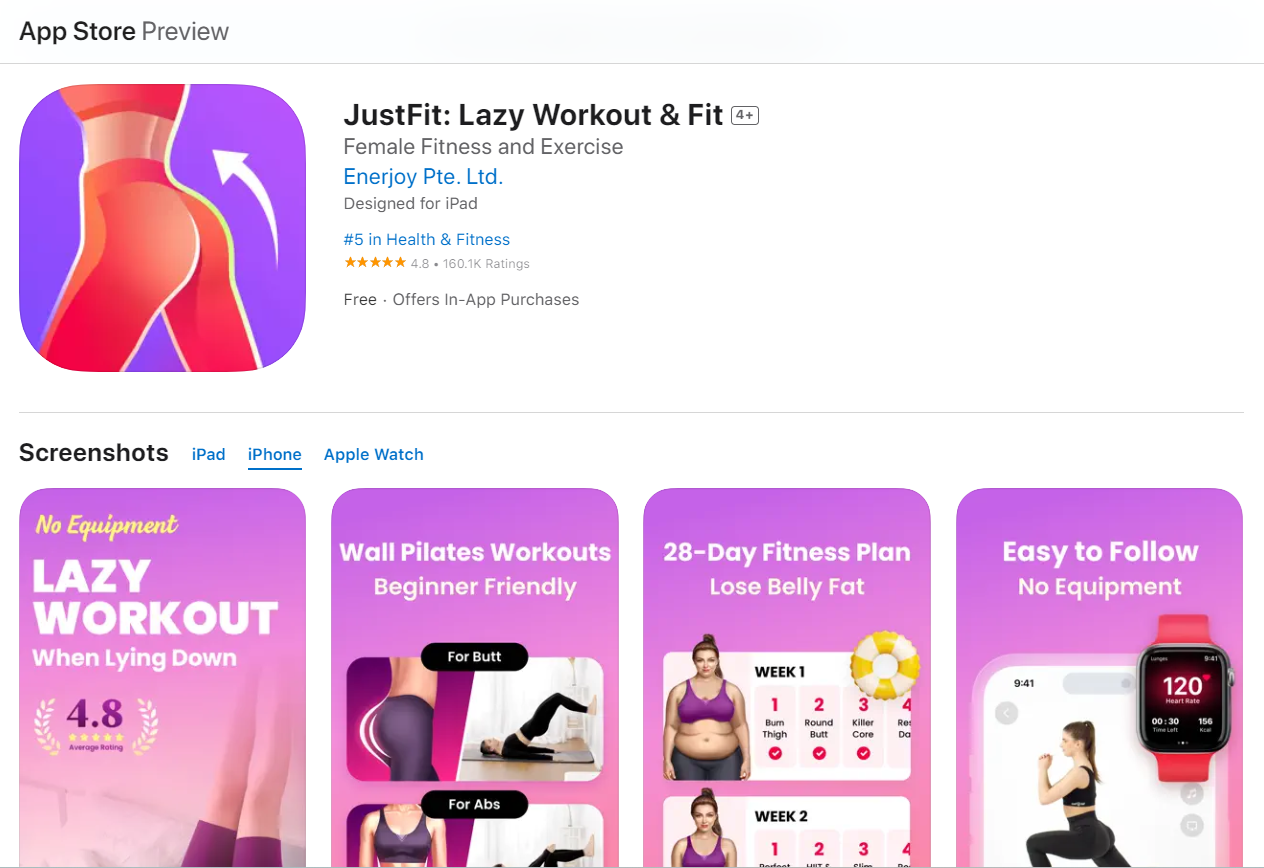
Основная идея - фитнес в домашних условиях, без дополнительного оборудования, наборы упражнений и фитнес план для каждого пользователя.
Мы добавляем его в аналитику ASOMobile и выбираем страну, для которой мы будем собирать семантическое ядро. Тут стоит упомянуть несколько нюансов.
N.B.
- семантическое ядро собирается отдельно для каждого магазина (так как ключевые слова имеют разные показатели трафика, популярности и т.д.)
- семантическое ядро собирается отдельно для каждой страны, по точно таким же причинам. Даже есть страна говорит на английском - и поисковые запросы и их параметры будут отличаться в США и в Великобритании).
Теперь возвращаемся в аналитику - основным полем для работы у нас будет несколько инструментов:
- App Keywords - здесь мы увидим все ключевые слова, по которому проиндексировано выбранное приложений. Чем их больше, тем лучше, но и про их качество тоже не стоит забывать.
- Keyword Monitor - сюда будут попадать все ключевые запросы, которые мы добавим в наше ядро. Уже на старте там будет тот список, который мы сформировали до работы с аналитикой, и еще туда можно добавить автоподсказки от системы.
- Keyword Finder, Keyword Select, Keyword Suggest, Suggest Checker - ряд инструментов по подбору ключевых слов.
- Text Analyzer - инструмент для анализа текста, который мы можем использовать для поиска ключевых слов в описаниях конкурентов.
А теперь начнем - добавляем приложения-конкурента, наш список запросов, пользуемся авто подсказкой от аналитики:
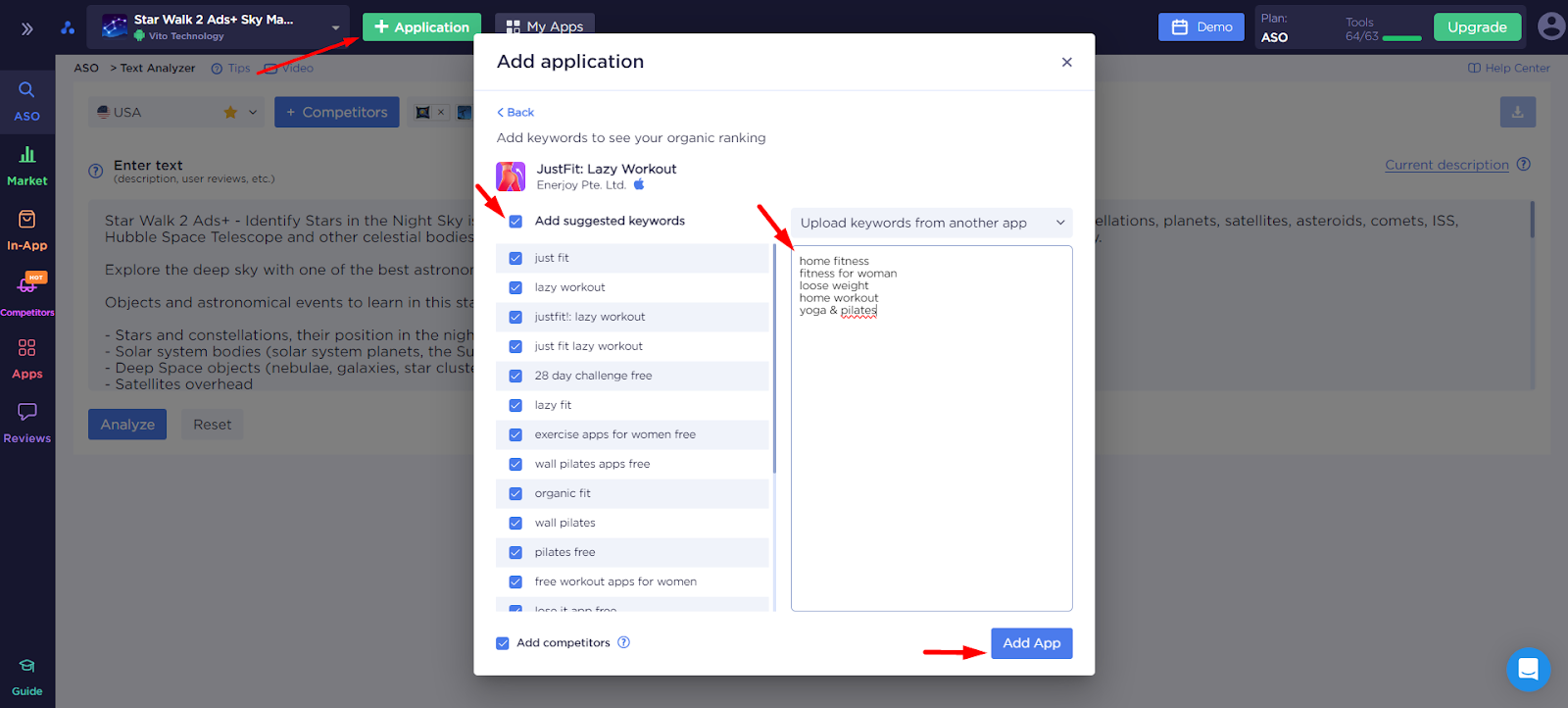
Уже на этом этапе мы можем зайти в Keyword Monitor и увидеть наше семантическое ядро, просто из поисковых запросов, которые мы добавили и авто подсказок системы. Обратим особое внимание на параметры ключевых слов, которые нам теперь доступны:
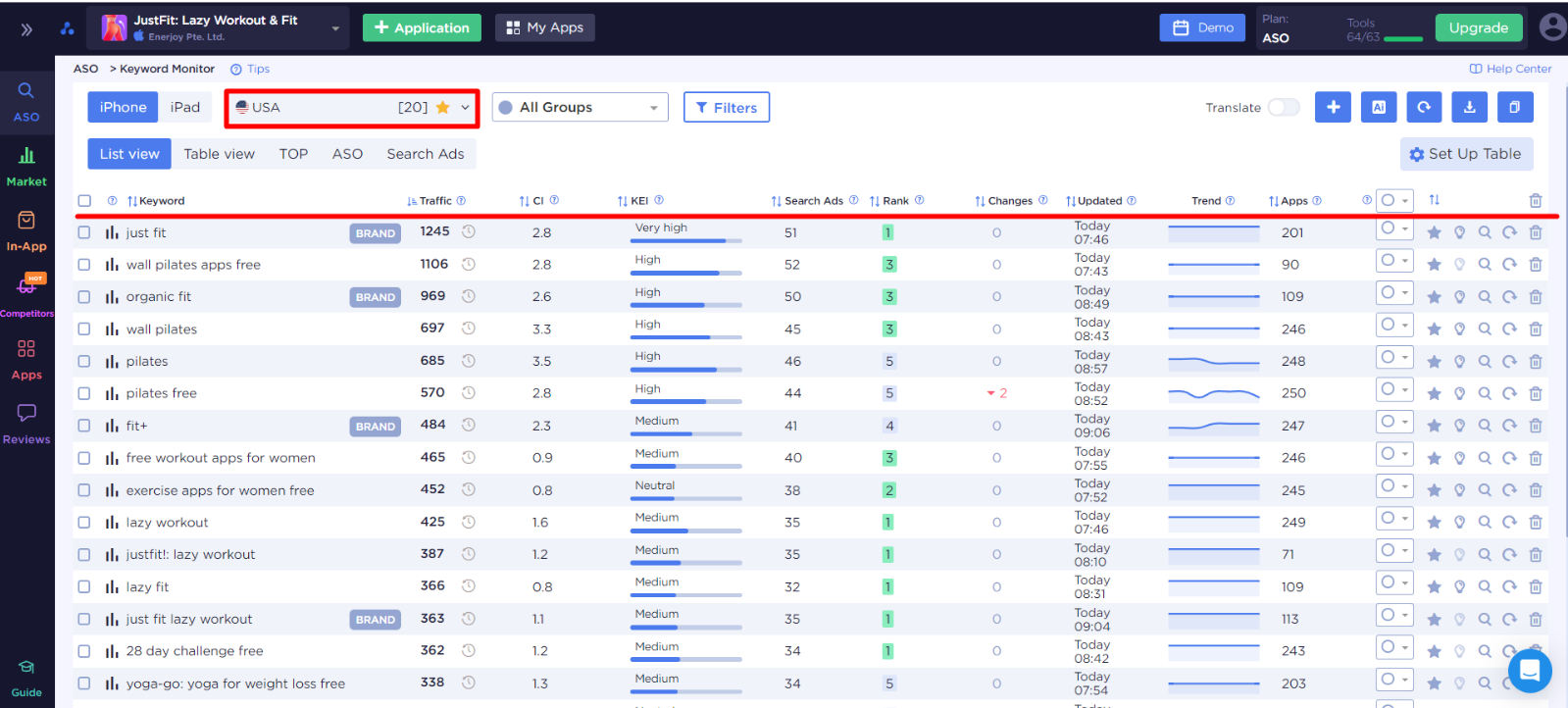
В нашем семантическом ядре для США, iOS - 20 поисковых запросов. Особое внимание мы уделим показателю трафика. Это количество пользователей в день, которые вводят в этой стране это ключевое слово в поиск магазина приложений.
Как видим мы из аналитики, поисковый запрос just fit в США ищут 1245 пользователей в день.
Предлагаем пока наполнить наше ядро максимальным количеством поисковых запросов, а потом перейти к процессу анализа и формированию окончательного списка ключевых слов.
Для этого, мы пойдем в главный инструмент - App Keywords, здесь будут все слова, по которым у нашего конкурента есть индексация. То, что нужно и нам, раз мы так похожи по функционалу. Индексация нашего конкурента - наш важный ориентир:
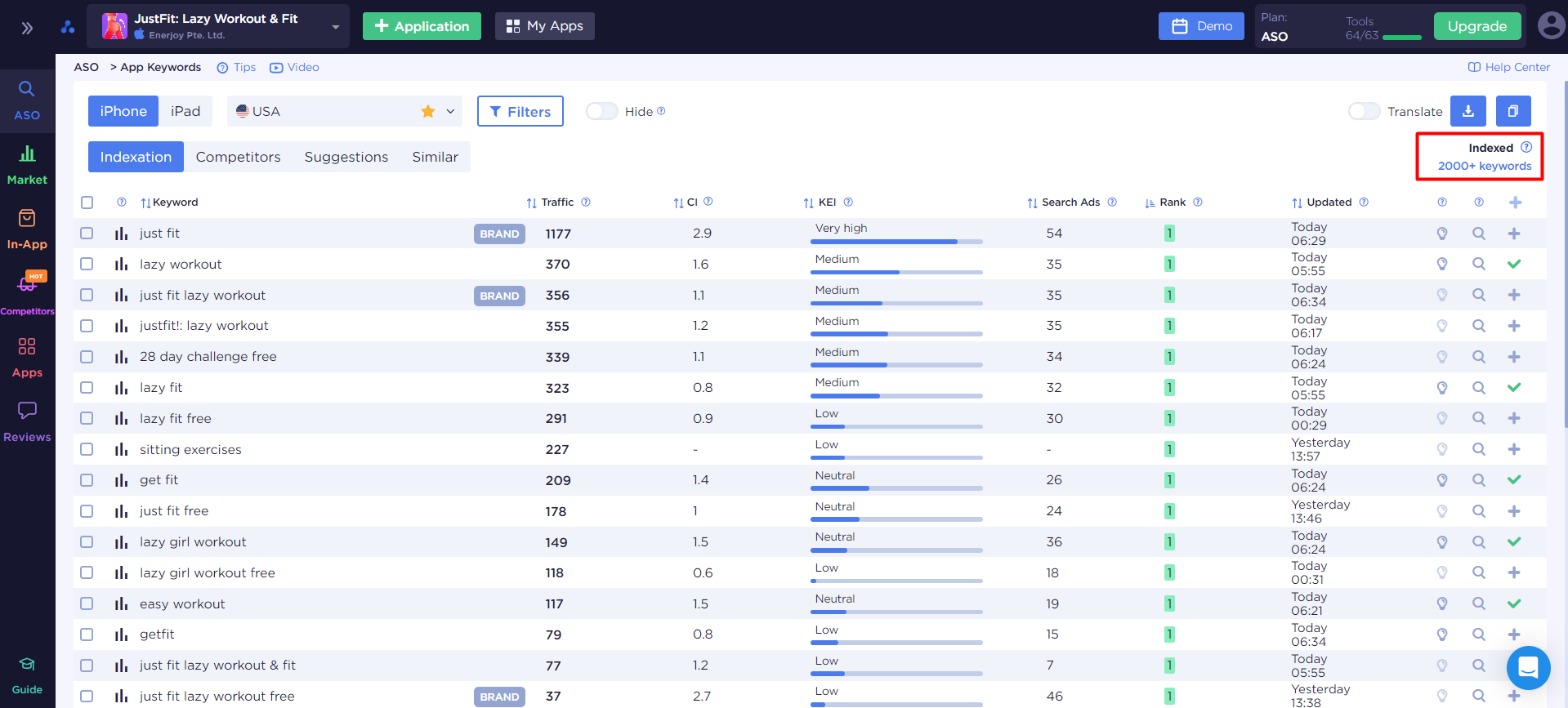
Мы пройдемся по всем поисковым запросам и добавим их в наше семантическое ядро, сомнения в их релевантности можно решить по ходу, или же потом, при работе с семантическим ядром. Каким образом мы будем проверять ключевое слов? Сомнения обычно возникают в нескольких случаях, такой запрос не пришел бы нам в голову, но пользователи есть и ключевое слово пользуется популярностью. Еще часто мы начинаем сомневаться, когда поисковый запрос не напрямую связан с нашим функционалом - проверяем мы его просто, смотрим, что происходит в поисковой выдаче и если там наши сплошные конкуренты, то стоит включить его в нашу семантику. Проверить поисковую выдачу мы можем непосредственно в аналитике:
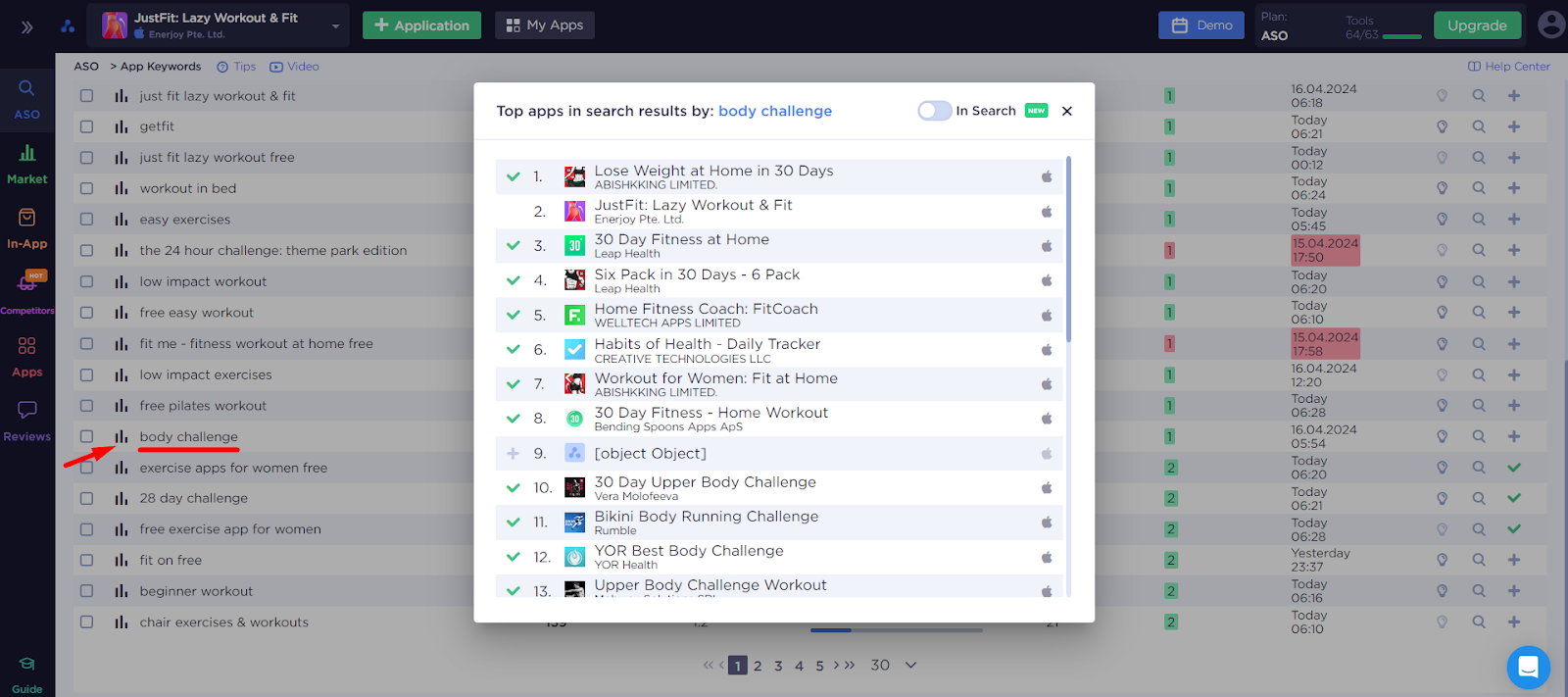
Поисковая выдача подтверждает, что это ключевое слово нам подходит, а кроме того, мы можем увидеть еще интересующих нас конкурентов и добавить их прямо из выдачи в аналитике. Так можно поступить с интересующими нас ключами - добавить конкурентов из выдачи, ведь они наш источник самой разнообразной и релевантной семантики.
Следующим шагом, мы воспользуемся остальными инструментами по поиску ключевых слов. Все имеют различный принцип работы, но просты и понятны в использовании:
- Keyword Finder - ориентируется уже на те слова, которые мы добавили в семантическое ядро и предлагает прочие релевантные варианты.
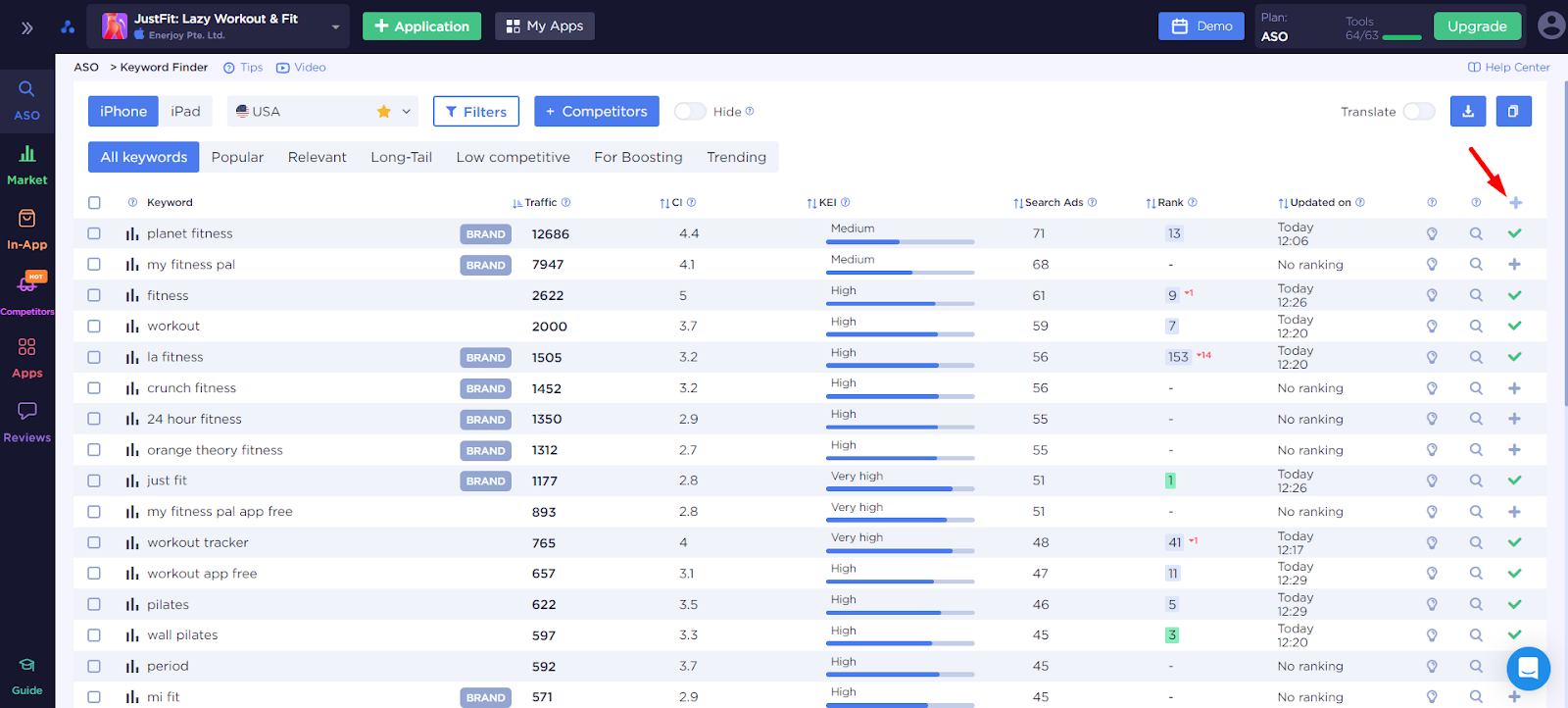
Мы добавим все, что кажется подходящим, релевантным и с трафиком. По последнему нужно обязательно ориентироваться, так как слова, которые никого не интересуют, не принесут пользу нашему приложения. В тоже время, включать в ядро только слова с очень высоким трафиком приведет к тому, что мы получим индексацию, но окажемся в самом самом конце списка выдачи и пользователи нас просто не найдут. Соблюдаем баланс, включаем в ядро поисковые запросы с различным показателями трафика.
- Keyword Select - потребует от нас вводной информации. Здесь необходимо указать поисковый запрос, который нас интересует и аналитика подскажет связанные ключевые слова.
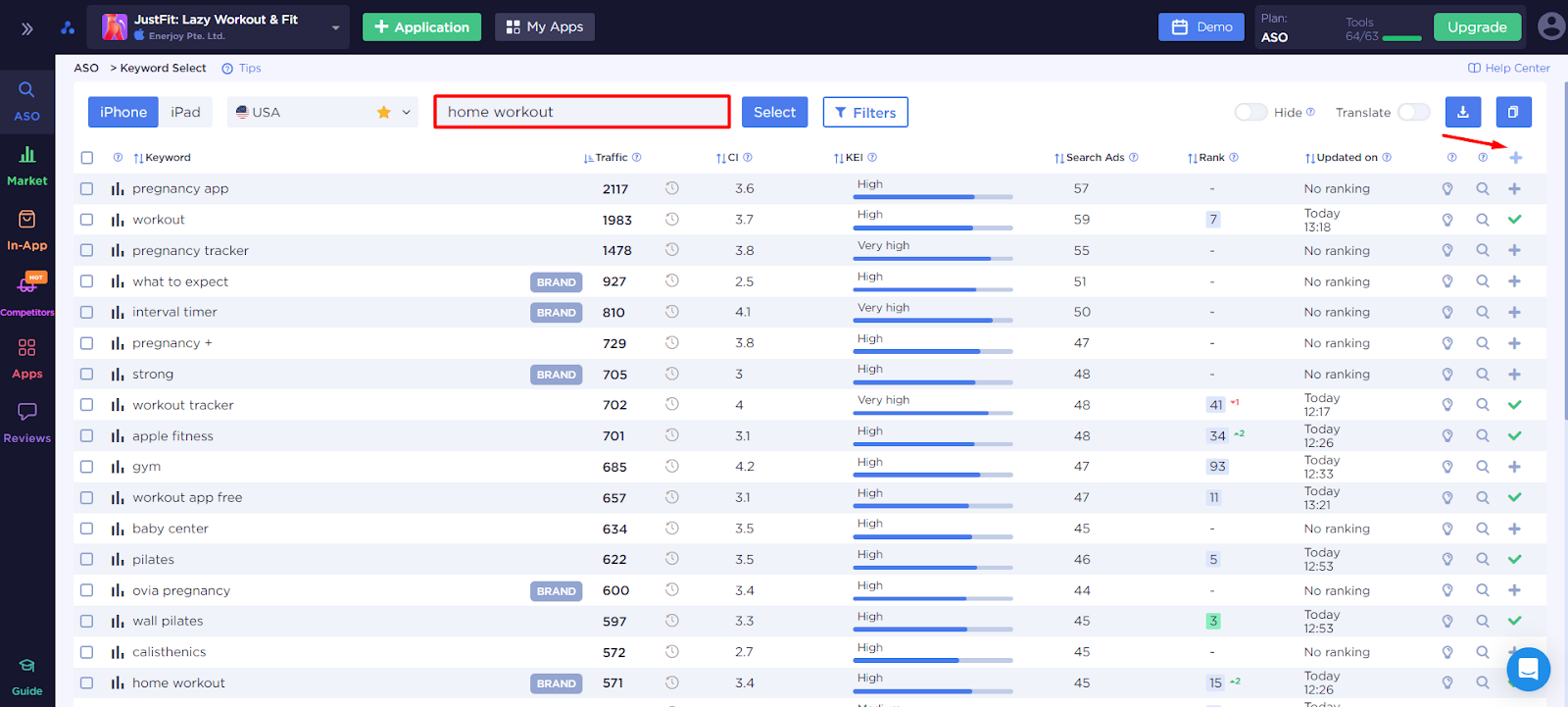
По очереди вводим интересующие нас ключевые слова, так как - home workout, fitness for women, fitness plan и дополняем наше семантическое ядро.
- Keyword Suggest - все подсказки магазина приложений в одном месте, на самом начальном этапе работы с семантикой, мы выяснили важную роль подсказок магазинов. Здесь мы сможем найти абсолютно все подсказки, по интересующим нас ключевым словам:
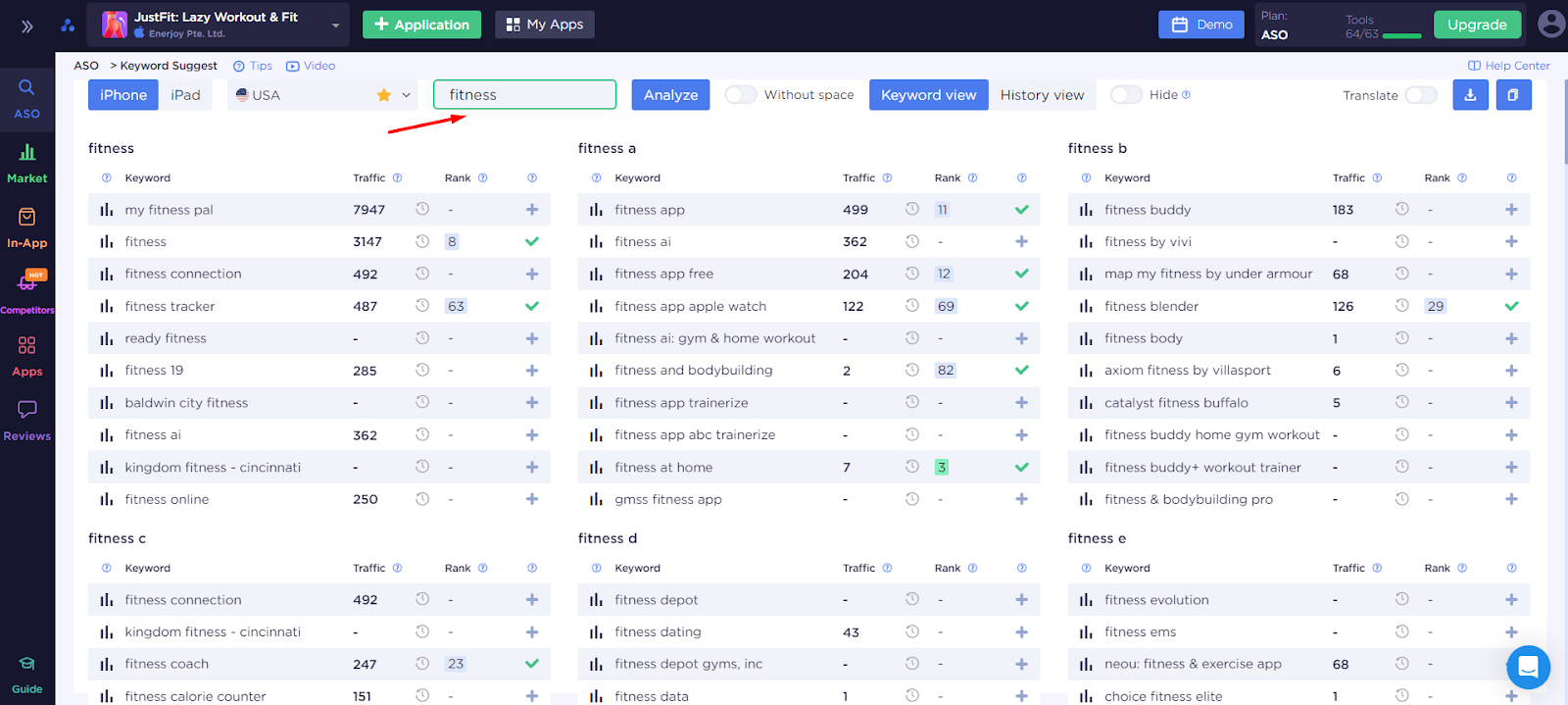
Все возможные ключевые фразы размещаются в алфавитном порядке, так что мы сможем выбрать подходящие запросы и добавить их в семантическое ядро.
А вот теперь, мы воспользуемся возможностями инструмента Text Analyzer, который проводит семантический анализ любого текста и определяет наличие в нем ключевых слов со всеми их характеристиками.
Первое, что мы проанализируем - это описание нашего основного конкурента, который выступает базой для оптимизации. Описание этого приложения уже есть в аналитике автоматически, так что остается только проанализировать:
Если ключевые слова нам подходят и еще не находятся в нашем семантическом ядре - смело добавляем.
В итоге мы получаем информацию про объем текста, количество использованных слов, но самое главное, про ключевые слова которые Text Analyzer обнаружил при сканировании этого описания.
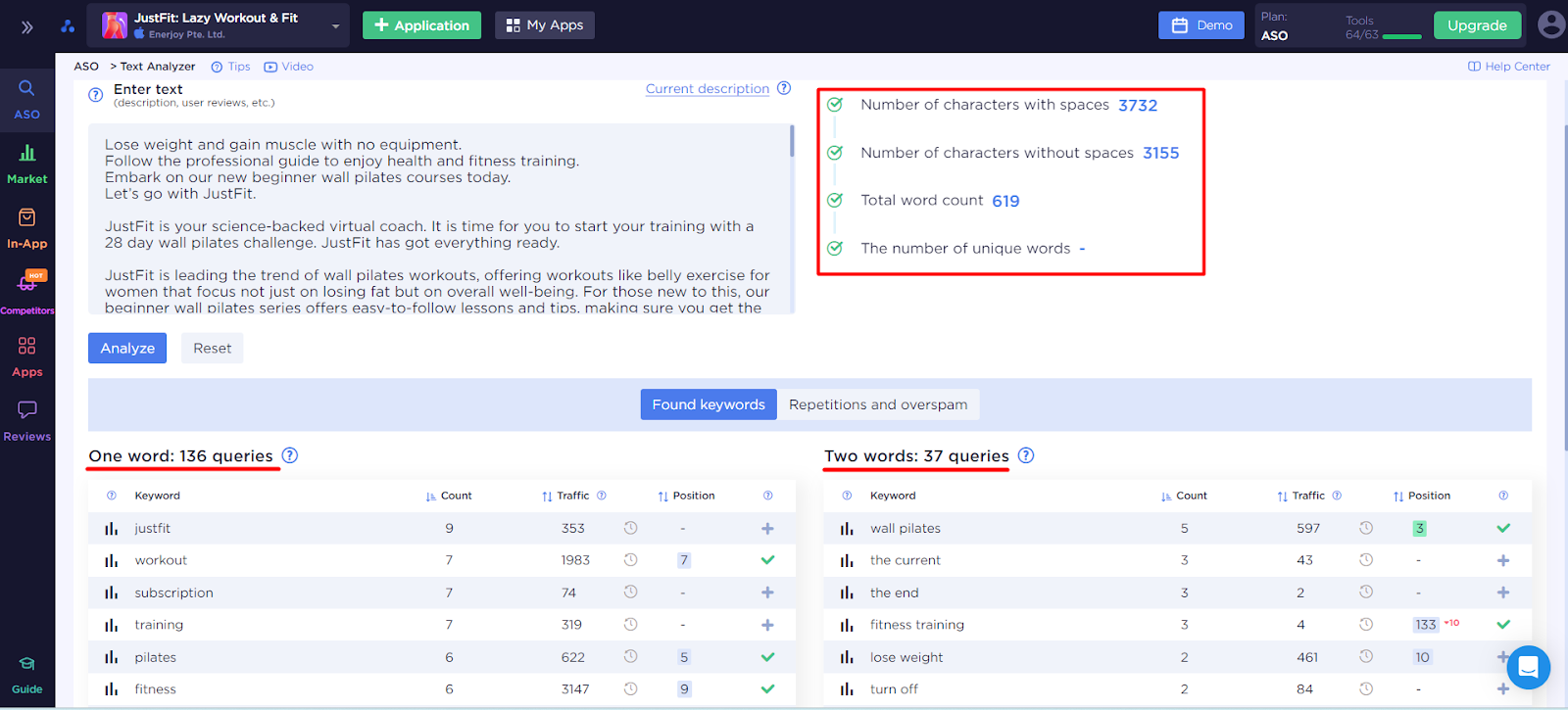
Кроме текущего описания, мы можем проанализировать описание любого другого приложения. А если понадобится, можно вручную вставить любой интересующий нас текст и получить исчерпывающий анализ.
Пора возвращаться к результату - черновое семантическое ядро со всеми добавленными ключевыми словами ждет нас в Keyword Monitor.
Анализ семантического ядра приложения
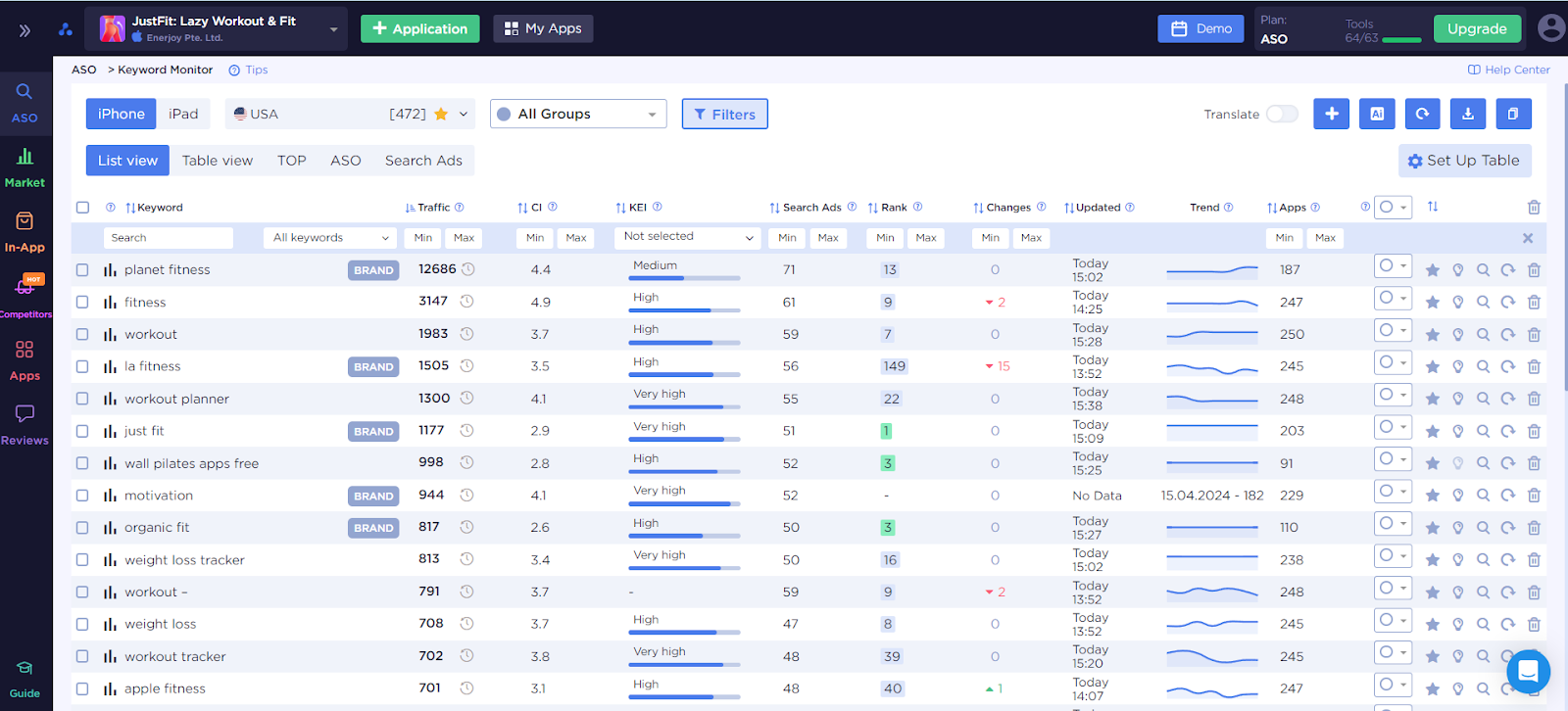
И вот мы сформировали очень длинный список ключевых слов, с трафиком, по которым проиндексированы наши конкуренты и они пользуются популярностью у пользователей этой ниши. Теперь мы будем следовать принципу релевантности - проверять каждый поисковый запрос на соответствие нашему функционалу. Тут стоит придерживаться следующих принципов:
- Не быть слишком конкретными, но и не распыляться. Если в нашем приложении нет счетчика калорий или рекомендаций по питанию, смело убираем эти запросы. Логика такая - конечно пользователи могут заинтересоваться и установить наше приложение, но по сути это вводит их в заблуждение. Не каждый, кто заинтересован в КБЖУ будет заинтересован в домашнем фитнесе. И такая не целевая установка приведет к удалению, низкой оценке и, самое печальное, к негативному отзыву.
- Четко очертить границы около целевых запросов - например пользователь может искать как похудеть, и скачать наше приложения с домашним фитнесом с этой целью. Но если пользователь больше заинтересован в йоге для успокоения ума и ментального здоровья, то для нашего приложения это будет около релевантный и совсем не целевой запрос. Балансируем, так как иногда пользователи сами не знают, чего хотят найти в маркете и мы показывается по широкому пулу ключевых слов. Но осторожничаем, не вводя пользователя в заблуждение.
- Оцениваем показатель трафика ключевого слова - как уже было сказано выше, избегаем слов с нулевым трафиком. Нет спроса - нет установок. Но если мы будем ориентироваться только на высокочастотные запросы, то это ведет к очень низкой позиции изначально с поисковой выдаче, очень высокой конкуренции за пользователей. А вот среднечастотные запросы - самые перспективные, ведь конкуренция не так уж и велика, а пользователи есть.
Теперь давайте пройдемся по нашему семантическому ядру - убираем все не релевантное (планы питания, счетчики калорий, ментальное здоровье, медитации и конечно же чужие бренды). Потом отсортируем все по показателю трафика, для удобства можно определить все запросы в три группы - высоко-, средне и низкочастотные. Более того, мы еще использовали цветовые метки для каждой из этих групп:
- 🟢 для запросов с самым высоким трафиком
- 🟠 для ключей со средним значением трафика
- 🟡 для поисковых запросов с низким трафиком
*цвета выбраны произвольно, любые совпадения случайны
Нет единого значения для определения этих показателей, шкала будет разной для разного типа приложения, ниш и категорий. Где-то 400 запросов в день будет в зеленой зоне, а где-то попадет в желтую.
Это же справедливо и для количества ключевых слова в семантическом ядре. Для приложения - калькулятор, мы даже и 60 запросов не наберем. А вот для Фото и видео редактора - легко перевалит за 150 ключей.
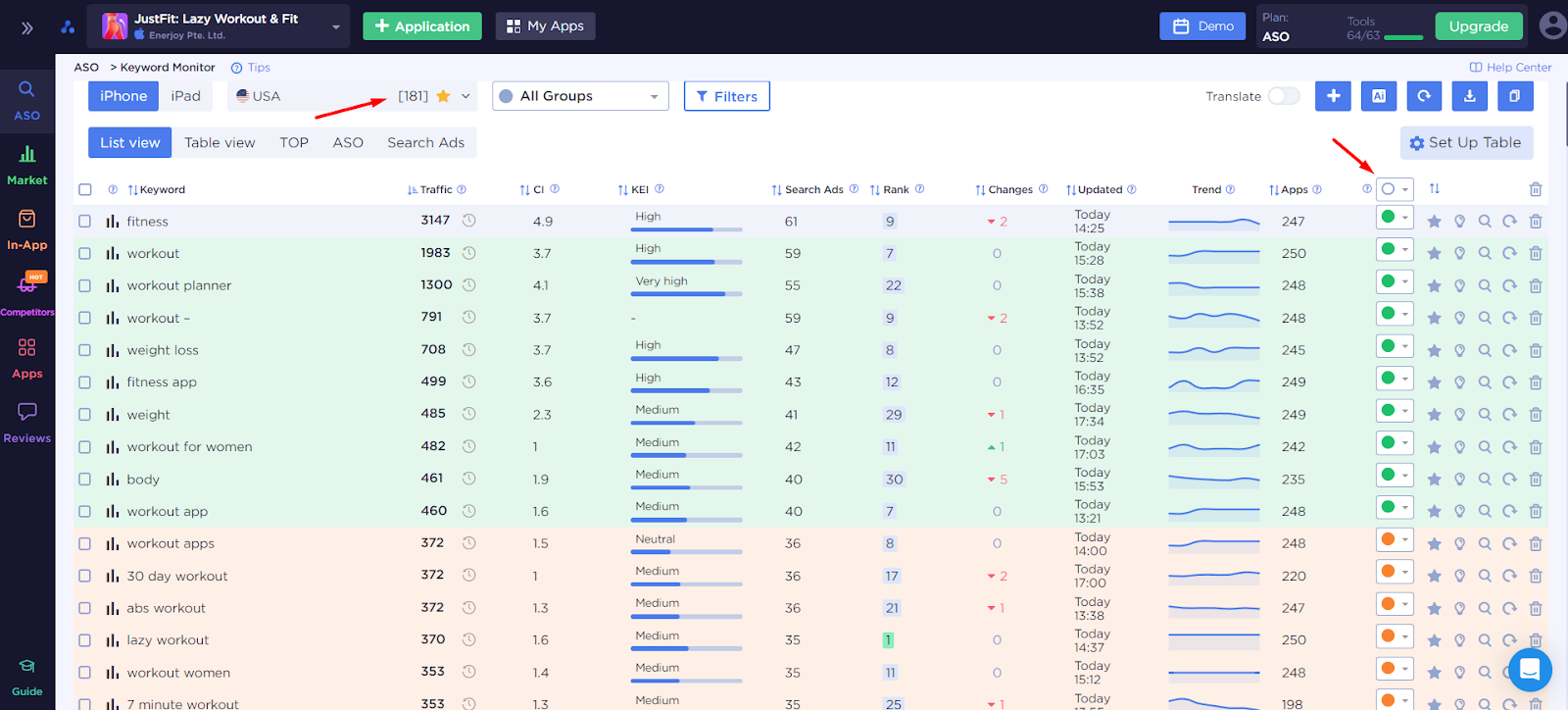
Вот так выглядит наше семантическое ядро, которое состоит из 183 ключевых запросов - результат нашего кропотливого труда.
Мы теперь разбираемся в источниках семантики, аналитических инструментах и видах ключевых слов и без труда сможем сформировать семантическое ядро для какого либо приложения или мобильной игры. Но что же дальше? А дальше необходимо разместить имеющиеся ключевые слова в метаданных приложения, по всем правилам и понятиям магазинов.
Здесь содержиться детальная и пошаговая инструкция по формированию метаданных приложения, как для Google Play, так и для App Store. Дальше будет не так трудоемко, но очень важно, ведь семантическое ядро, даже самое релевантное и тщательно выверенное, не приведет нас к желанной цели - к индексации.
Оптимизируйте и достигайте успеха💙
Это массив ключевых слов и фраз, которые наилучшим образом описывают приложение, все релевантные ассоциации. ASO специалисты внедряют этот список ключевых в метаданные для улучшения видимости приложения в поиске (ASO оптимизация). Введя любое из этих ключевых слов а в строке маркета, пользователь сможет найти оптимизированное приложение.
Количество поисковых запросов в семантическом ядре не регулируется и зависит от категории приложения, его функционала и запросов пользователей. Главное, чтобы собранные ключевые слова были релевантными (т.е. соответствовали функционалу) и востребованными (трафик) у пользователей.
Логика, подсказки магазинов и аналитические инструменты, такие как ASOMobile. Последние не только помогут найти ключевые слова, но и помогут в их анализе (с точки зрения важнейших показателей - трафик, релевантность и сложность).
Брендовые поисковые запросы - это запросы, которые пользователи вводят в поисковые системы для поиска конкретного бренда или компании. Эти запросы обычно включают название бренда или его вариации. Брендовые запросы часто имеют высокий уровень конверсии, поскольку пользователи, уже знакомые с брендом, активно ищут конкретные продукты или информацию о нем.
